
Retrieval Augmented Generation (RAG) ergänzt das Generieren eines Large Language Models (LLM, auf Deutsch: großes Sprachmodell) durch eine gute Suche, z.B. in einer Dokumentensammlung, in einer Datenbank oder in einem Knowledge Graph. Hierdurch lässt sich die Verlässlichkeit (Dependable AI) des Generierens deutlich steigern und gleichzeitig wird es möglich, das Potenzial von Large Language Models für eigene (interne) Dokumente und Daten zu nutzen – ganz ohne Fine-Tuning.
Large Language Models (LLM) können viele Fragen erstaunlich gut beantworten – zumindest auf den ersten Blick. Dies ist möglich, da beim Training der Modelle auch Wissen aus den Trainingsdaten in den Parametern der LLM gespeichert wird. Allerdings sind LLM primär Textgeneratoren und bringen keinen Mechanismus mit, um dieses »nebenbei« angeeignete Wissen gezielt abzurufen.
Bei aktuellen und hinreichend großen Large Language Models funktioniert das Beantworten von Wissensfragen zu allgemein bekannten Themen auch ohne weitere Hinzunahme zusätzlicher Quellen meist recht gut. Aber auch nicht immer. Manchmal schleichen sich Fehler ein, es werden wichtige Punkte vergessen oder das LLM erfindet Fakten – man spricht hierbei auch von Halluzinationen (siehe Ji et al. (2023): Survey of Hallucination in Natural Language Generation). Eine eindrucksvolle Darstellung davon, wie das Vortraining mit den Problemen zusammenhängt, findet sich bei McCoy et al. (2023): Embers of Autoregression: Understanding Large Language Models Through the Problem They are Trained to Solve.
In der Literatur finden sich viele Techniken zum Identifizieren von Halluzinationen, z. B. SelfCheckGPT, aber auch zu deren Vermeidung. Eine verbreitete und hilfreiche Methode ist Retrieval Augmented Generation (RAG) (siehe auch Shuster et al (2021): Retrieval Augmentation Reduces Hallucination in Conversation). In einem ganz aktuellen Paper untersuchen Wu et al. (2024) die Frage, in welchem Maße RAG wirklich hilft, Halluzinationen eines LLM zu verhindern.
Was ist Retrieval Augmented Generation (RAG)?
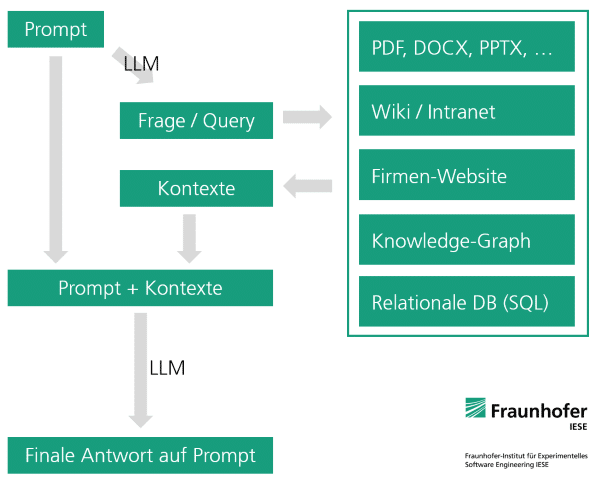
Auf Deutsch bedeutet Retrieval Augmented Generation (RAG) Generieren [z.B. von Text] ergänzt durch Abrufen [von Informationen]. Konkret bedeutet dies, dass einem LLM mittels einer guten Suche Wissensquellen zur Seite gestellt werden. Hierdurch muss das Wissen, das zur Beantwortung eines Prompts erforderlich ist, nicht mehr aus dem LLM kommen, sondern es wird den angebundenen Quellen entnommen. Die Aufgabe des Large Language Models besteht dann nur noch darin, die Suchergebnisse im Sinne der ursprünglichen Anfrage (des Prompts) zu verwerten, z.B. zusammenzufassen. Ein modernes LLM kann mithilfe eines dem Prompt hinzugefügten Textes sehr zuverlässig Fragen beantworten bzw. andere Aufgabenstellungen lösen – viel zuverlässiger, als wenn es auf implizit angeeignetes Wissen zurückgreifen muss.
RAG kann internes Wissen Ihres Unternehmens besser zugänglich machen: »Mit eigenen Dokumenten chatten«
Retrieval Augmented Generation (RAG) ergänzt Large Language Models nicht nur mit dem Zweck, Halluzinationen zu vermeiden und zuverlässiger zu antworten. RAG eignet sich auch hervorragend dafür, Fragen zu internen Dokumenten und/oder anderen Daten mithilfe eines Large Language Models zu beantworten. Jedes moderne und hinreichend große Large Language Model kann mithilfe von RAG ohne Fine-Tuning dazu benutzt werden, Antworten auf Grundlage von internen Dokumenten bzw. Datenbanken zu generieren. Stark vereinfacht gesagt: Durch RAG wird es möglich, mit eigenen Dokumenten bzw. Daten zu chatten.
Welche Quellen lassen sich für RAG anbinden?
Oft wird Retrieval Augmented Generation mithilfe einer semantischen Suche für Dokumentensammlungen realisiert. Diese stellt semantisch passende Passagen aus Textsammlungen bereit.
Manchmal ist anstelle einer Vektorsuche auch eine fuzzy (unscharfe) String-Suche sinnvoll, die z. B. mit Elasticsearch, OpenSearch oder Apache Solr für den Produktivbetrieb implementiert werden kann. Wir haben gute Erfahrungen mit einer hybriden Suche gemacht: einer Kombination aus semantischer Vektorsuche und fuzzy Keyword-Suche mit OpenSearch.
Letztlich kann aber jede Art von Datenbank und Suche (z. B. auch eine Internetsuche) für RAG genutzt werden, solange die Suchergebnisse als Textabschnitte dargestellt werden können; Beispiele hierfür sind Wissensgraphen (Knowledge Graph) und relationale Datenbanken (SQL-Datenbanken). Um diese Datenquellen nutzen zu können, erzeugt das Large Language Modell (es kann auch ein zweites, spezialisiertes LLM zum Einsatz kommen) eine Datenbankabfrage in der erforderlichen Abfragesprache, z. B. SQL, Cypher oder SPARQL. Der Einsatz solcher Datenquellen kann sinnvoll sein, wenn diese sowieso schon in einem Unternehmen existieren und mithilfe des LLM zugänglich gemacht werden sollen, oder wenn Fragen beantwortet werden sollen, die nicht auf Grundlage der Top-Treffer in einer Dokumentendatenbank beantwortet werden können, z. B. »Wie viele Projekte hat das Fraunhofer IESE im Jahr 2022 erfolgreich abgeschlossen?«, oder für Fragen, für die eine reine Dokumentendatenbank mehrfach durchsucht werden müsste, sogenannte Multi-Hop-Fragen.
Wie lassen sich Datenbanken für RAG anbinden?
Zur Herstellung der Verbindung von LLM und Datenbank gibt es umfangreiche Open-Source-Bibliotheken, z.B. LangChain und LlamaIndex. Man kann die Anbindung aber auch mit wenig Aufwand selbst programmieren, was die Möglichkeit bietet, auf Besonderheiten des Use Cases einzugehen. Zum Beispiel kann man so eine automatische Synonymersetzung integrieren, um die Suche zu verbessern. Unser Team Data Science kann hierbei unterstützen.
Welches LLM ist für Retrieval Augmented Generation geeignet?
Grundsätzlich lässt sich Retrieval Augmented Generation mit allen Large Language Models kombinieren, die programmatisch, z. B. über eine API, zugänglich sind. Es ist also möglich, sowohl kommerzielle LLM als auch selbstbetriebene Open-Source Large Language Models (on-premises) zu nutzen. Auch hierbei helfen Bibliotheken wie LangChain oder LlamaIndex. Sowohl instruction-tuned als auch chat-tuned LLM eignen sich unserer Erfahrung nach für RAG.
Sensible Daten mit einem Open-Source LLM verarbeiten (on-premises)
Open-Source Large Language Models bieten viele Vorteile gegenüber kommerziellen Angeboten. Im Kontext von Retrieval Augmented Generation ist aber sicherlich ein besonders wichtiger Vorteil, dass diese on-premises selbst betrieben werden können, denn RAG soll ja häufig mit internen sensiblen Daten genutzt werden (bei jeder Anfrage müssen dem LLM also interne sensible Daten übermittelt werden). Mit einem selbstbetriebenen (on-premises) Open-Source Large Language Model ist sichergestellt, dass während dessen Benutzung zu keinem Zeitpunkt sensible Daten das eigene Netzwerk verlassen müssen. Die gesamte Datenverarbeitung kann auf der eigenen Infrastruktur stattfinden.
Einige weitere Vorteile:
- Spezialisierte LLM können zum Einsatz kommen, z. B. für SQL
- Auf Deutsch spezialisierte LLM können zum Einsatz kommen, z. B LeoLM 70B Chat, SauerkrautLM – Mixtral – 8x7B, oder DiscoLM Mixtral 8x7b
Was ist bei der Auswahl eines LLM zu beachten?
Unabhängig davon, ob man sich für ein kommerzielles oder ein Open-Source LLM entscheidet: Im Zusammenhang mit RAG ist einiges zu beachten. Besonders wichtig ist, dass das LLM einen langen Prompt verarbeiten kann. Darüber hinaus ist für manche Schritte im RAG-Algorithmus ein besonders gutes Instruction-Tuning notwendig: Soll beispielsweise eine Suchphrase aus dem Prompt generiert werden, darf das Modell einerseits natürlich nicht halluzinieren, vor allem aber darf es nicht noch Erklärungen, Notizen oder gar eine Entschuldigung hinzufügen. Beim Beantworten des ursprünglichen Prompts hingegen darf das Modell ruhig etwas redseliger sein.
Wir haben gute Erfahrungen mit dem Einsatz zweier LLMs innerhalb einer RAG Pipeline gemacht: ein großes, eloquentes LLM, das einen großen Prompt verarbeiten kann (z. B. Mixtral – 8x7B – Instruct), und ein kleines, schnelles LLM, das sehr präzise Anweisungen befolgen und sehr präzise antworten kann (z. B. Nous Hermes 2 – SOLAR 10.7B). Nicht zuletzt ist natürlich auch wichtig, für welche Sprachen ein Modell vorbereitet wurde. Während beispielsweise das Erfassen deutschsprachiger Texte für die meisten modernen LLM kein Problem mehr ist, merkt man zumindest kleineren Modellen beim Generieren von Texten schon deutlich an, ob ein Fine-Tuning für Deutsch stattgefunden hat.
Weitere Blog-Beiträge zum Thema Large Language Models (LLM):
- Was sind Large Language Models? Und was ist bei der Nutzung von KI-Sprachmodellen zu beachten?
- Halluzinationen von generativer KI und großen Sprachmodellen (LLMs)
- Open Source Large Language Models selbst betreiben
- Large Action Models (LAMs) nutzen neurosymbolische KI – Die nächste Stufe im Hype rund um Generative AI
- Die Zukunft des Sprachassistenten: Datenhoheit durch Spracherkennung mit eigenem LLM Voice Bot
- Prompt Engineering: wie man mit großen Sprachmodellen kommuniziert
Ist Fine-Tuning eine Alternative zu Retrieval Augmented Generation?
Vor dem Jahr 2023, das Huggingface als »year of open LLMs« bezeichnet, gehörte Fine-Tuning zu den ganz typischen Aufgaben beim Einsatz von Sprachmodellen wie BERT. Kein Wunder also, dass man sich auch im Jahr 2024 noch fragt, ob Fine-Tuning nicht helfen könnte, das Wissen aus Dokumenten einem LLM zur Verfügung zu stellen. Unserer Ansicht nach sollte Fine-Tuning aber nicht dafür eingesetzt werden, einem LLM Wissen anzutrainieren.
Im Zusammenhang mit RAG kann Fine-Tuning aber durchaus helfen, z.B. um
- einen bestimmten Antwortstil zu berücksichtigen,
- auf bestimmte Details in den Suchergebnissen zu achten,
- mit speziellen Suchergebnisformaten besser umgehen zu können, z. B. Ergebnissen aus einer relationalen Datenbank (»SQL«) oder aus einem Knowledge Graph.
Fine-Tuning kann also RAG durchaus ergänzen. Mit Parameter Efficient Fine-Tuning, z.B. LoRA oder QLoRA, ist dies im Jahr 2024 auch mit moderaten Hardwareanforderungen technisch machbar. Man sollte aber nicht vergessen, dass Fine-Tuning ein sehr aufwändiges Vorhaben ist. Ein Fine-Tuning durchzuführen, das insgesamt wirklich zu einer Verbesserung der Modellqualität führt, ist nicht einfach. Unser Team Data Science kann Sie hierbei unterstützen und auch Alternativen aufzeigen.
Wir empfehlen, zuerst die Möglichkeiten von Retrieval Augmented Generation auszureizen und möglichst viel in dieser Hinsicht zu optimieren.
Vom Ausprobieren zur Produktion
Retrieval Augmented Generation auszuprobieren ist nicht schwierig. Mit LangChain oder LlamaIndex hat man schnell sein Lieblings-LLM, eine Vektordatenbank mit Embedding-Modell und einen Dokumenten-Importer miteinander verbunden. In einem Jupyter-Notebook kann man dann Anfragen an dieses RAG-System stellen. Es gibt auch schon fertige Open-Source Software für RAG, z. B. PrivateGPT und AnythingLLM, und auch Cloud-Angebote für RAG stehen bereit. Auch interessant für den Einstieg: Im Februar 2024 hat NVIDIA »Chat with RTX« vorgestellt, eine kostenlose RAG Demo App (siehe auch den Newsartikel bei Heise).
Unserer Ansicht nach kann so etwas aber nur den Einstieg in das Thema darstellen. Um ein RAG-basiertes System richtig gut zu machen und genau auf den eigenen Use Case zuzuschneiden, ist viel Detailarbeit erforderlich. Und nicht zuletzt wird ja ein System angestrebt, das Server-basiert einer großen Anzahl von Mitarbeitenden bereitgestellt werden kann und dabei möglichst auch on-premises betrieben werden soll. Unser Team Data Science hat viel Erfahrung beim individuellen Gestalten und Optimieren sowie beim Betrieb (on-premises) von Retrieval-Augmented-Generation-Systemen und kann Sie bei der Umsetzung unterstützen.
Evaluieren eines Retrieval-Augmented-Generation-Systems
Bevor man anfängt zu optimieren, sollte man eine Evaluation aufsetzen, um die Qualität des Retrieval-Augmented-Generation-Systems zu messen. Man kann auf der Ebene arbeiten, Prompts mit den finalen Ausgaben zu vergleichen oder auch generierte Ausgaben mit den Antworten eines Testdatensatzes; man kann aber auch zunächst validieren, ob die Suche des RAG-Systems die richtigen Dokumente findet. Ein Open-Source Tool, das speziell zum Evaluieren von RAG-Systemen gemacht ist, ist RAGAS.
Ist Retrieval Augmented Generation das Richtige für Ihren Anwendungsfall?
Retrieval Augmented Generation ist nicht die einzige Möglichkeit, um interne Dokumente mithilfe von Large Language Models zugänglich zu machen. Insbesondere wenn es darauf ankommt, dass keinesfalls Halluzinationen in der finalen Antwort auftreten dürfen, ergibt es Sinn, über verlässlichere Alternativen nachzudenken. Unser Team Data Science unterstützt Sie hierbei gerne.
Unterstützung durch unser Data-Science-Team
Retrieval Augmented Generation ist unserer Ansicht nach eine hervorragende Möglichkeit, um die Leistungsfähigkeit von Large Language Models für eigene Dokumente und Datenbanken zu nutzen; speziell die Anbindung eines Knowledge Graph bietet unserer Ansicht nach sehr viel Potenzial. Unser Team Data Science hilft Ihnen gerne bei der Umsetzung, insbesondere bei folgenden Punkten:
- Use-Case-spezifische Auswahl eines (oder mehrerer) Large Language Models
- Use-Case-spezifische Anbindung existierender Datenbanken, Knowledge Graphs oder Dokumente
- Use-Case-spezifische Vorverarbeitung der Daten (Preprocessing)
- Aufsetzen eines production-ready Systems, selbstverständlich auch on-premises, mithilfe von Open-Source Large Language Models
- Use-Case-spezifische Evaluierung des Systems
- Use-Case-spezifische Optimierung
- Falls erforderlich: Use-Case-spezifisches Fine-Tuning
- Knowledge Transfer und Schulung Ihrer Mitarbeitenden
Sie wünschen einen persönlichen Beratungstermin?
Schreiben Sie uns gerne eine E-Mail!
Wir können dann ganz unverbindlich über Ihren Use Case sprechen.
Large Language Models Webinare
Wie kann ich mehr über LLMs lernen?
Das Team Data Science bietet zum Thema LLM Webinare an, darunter sowohl kostenfreie als auch kostenpflichtige Optionen.
Mehr zur Webinarreihe
»Zuverlässiger Einsatz von Large Language Models (LLMs)«
1: Open Source LLMs selbst betreiben
2: Retrieval Augmented Generation (RAG)
3: Prompting Essentials – LLMs effektiv nutzen
Sie haben Interesse an einem Seminar für Ihr Unternehmen?
Auf Wunsch bieten wir individuell gestaltete Seminare (auf Deutsch und Englisch) für Ihr Unternehmen an, in denen die Schulungsinhalte gezielt auf Ihre Bedürfnisse abgestimmt werden können.