
Generative Künstliche Intelligenz (KI) und insbesondere Large Language Models (LLMs) haben das Potenzial, unsere Interaktion mit Technologie und Wissensmanagement grundlegend zu verändern. Generative KI-Modelle sind in der Lage, menschenähnliche Inhalte (Text, Bilder, Audio, Video) zu erzeugen, was sie für viele Anwendungen nützlich macht. Sie sind jedoch nicht frei von Schwächen. Ein zentrales Problem sind KI-Halluzinationen, die sowohl die Zuverlässigkeit der Modelle als auch ihre praktische Anwendbarkeit gefährden.
Was sind KI-Halluzinationen?
Halluzinationen im Zusammenhang mit KI beziehen sich auf von einem KI-Modell generierte Inhalte, die zwar realistisch erscheinen, aber von den vorgegebenen Quelleninputs abweichen. Man spricht von fehlender Übereinstimmung (faithfulness) oder mangelnder faktischer Richtigkeit (factualness).
Beispiele für Halluzinationen bei KI

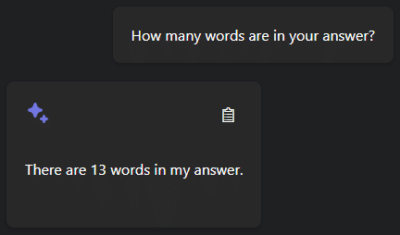
Solche Halluzinationen können in kritischen Bereichen wie der Medizin oder dem Rechtssystem schwerwiegende Folgen haben, wenn falsche Informationen für wahr gehalten werden.
Ursachen von Halluzinationen bei KI-Modellen
Es gibt mehrere Faktoren, die zum Auftreten von Halluzinationen beitragen:
- die Trainingsdaten,
- die Art und Weise, wie das Modell trainiert wird (Trainingsmethoden),
- die Art und Weise, wie das Modell Inhalte generiert (Inferenz).
Trainingsdaten:
Fehlerhafte Datenquellen spielen eine zentrale Rolle. Trainingsdaten können Ungenauigkeiten oder Stereotypen enthalten, die zu einer fehlerhaften Repräsentation der Realität führen. Ohne geeignete Vorsichtsmaßnahmen erzeugen datenbasierte Lösungen Verzerrungen (siehe z.B.[1]).
Sind die Trainingsdaten nicht aktuell, werden neuere Entwicklungen oder Erkenntnisse nicht berücksichtigt. Dies schränkt die Relevanz und Genauigkeit der Antworten erheblich ein.
Ein weiterer Aspekt ist die Fachspezifik. Oft enthält das Trainingsdaten-Set kein spezialisiertes Wissen. Dies kann zu KI-Halluzinationen führen. Das Modell hat nicht die nötigen Informationen, um präzise Antworten zu geben.
Dies wird durch die unzureichende Nutzung von Faktenwissen noch verstärkt. Die Modelle stützen sich häufig auf Korrelationen statt auf kausale Effekte. Dies führt zu oberflächlichen Analysen. Bei komplexen Fragestellungen können diese Abkürzungen falsche oder irreführende Ergebnissen erzeugen.
Das »Needle in a Haystack«-Problem tritt auf, wenn relevante Fakten in einer großen Datenmenge versteckt sind. Ein Beispiel dafür sind umfangreichen Bibliographien. Das Modell hat dann Schwierigkeiten, die richtigen Informationen zu filtern. Komplexe Szenarien, wie Multi-hop Q&A, zeigen die Grenzen der Schlussfolgerungsfähigkeit. Das passiert selbst dann, wenn alle notwendigen Informationen vorhanden sind.
Trainingsmethoden:
Bei den Trainingsmethoden sind mehrere Faktoren zu berücksichtigen. Schwachstellen in der Architektur, wie z.B. »Attention Glitches«, können zu Inkonsistenzen in den Ergebnissen führen. Darüber hinaus gibt es Unterschiede zwischen den Trainings- und Inferenzstrategien, die als »Exposure Bias« bekannt sind und dazu führen, dass das Modell in der Praxis nicht optimal arbeitet.
Auch die Anpassung durch »Fine-Tuning« und »Instructions-Tuning«, wie z.B. »Reinforcement Learning through Human Feedback« (RHLF), hat ebenfalls ihre Grenzen. Ein Beispiel dafür ist das Phänomen der »Sycophancy«, bei dem das Modell übermäßig dazu neigt, den Erwartungen der Nutzer zu entsprechen, statt objektive Informationen zu liefern [2].
Inferenz:
Inferenz in der KI bezieht sich auf den Prozess, bei dem ein trainiertes Modell verwendet wird, um Vorhersagen zu treffen oder Entscheidungen auf Basis neuer Daten zu treffen. Zum Beispiel, wenn man ChatGPT benutzt, um eine Frage zu stellen, wird das Modell benutzt, um eine Antwort auf der Basis des eingegebenen Textes zu generieren (dies ist die „Inferenzzeit“).
Die Inferenzmethoden spielen eine entscheidende Rolle. Die Dekodierungsstrategien sind häufig stochastisch. Während Token-Sequenzen mit hoher Wahrscheinlichkeit zu beispielsweisen schlechten Texten führen (die sogenannte »Likelihood-Trap«), kann eine zu starke Randomisierung zu Halluzinationen führen, da das Modell unplausible Inhalte produziert.
Es gibt verschiedene Token-Typen, die Halluzinationen in Sprachmodellen verursachen können. Zum Beispiel können ähnliche numerische Werte wie Preise (9,99 EUR; 10,00 EUR), nahe beieinander liegende Daten (2020, 2021), ähnlich klingende Namen, oder technische Begriffe und Abkürzungen (KI, ML) problematisch sein. Diese Token-Typen haben häufig ähnliche Wahrscheinlichkeiten, was die Auswahl des korrekten Tokens erschwert.
Phänomene wie »Over Confidence« und »Instruction Forgetting« beschreiben, wie das Modell zu stark auf lokale Wörter fokussiert und dabei den Gesamtzusammenhang verliert. Der »Softmax Bottleneck« stellt eine technische Limitierung dar, die die Vielfalt der generierten Antworten einschränkt.
KI-Halluzinationen erkennen
Das Erkennen von Halluzinationen ist entscheidend für die Verbesserung der Genauigkeit und Zuverlässigkeit der erzeugten Antworten. Das Erkennen von Halluzinationen ist nicht trivial, und verschiedene Strategien sind möglich.
Unsicherheit messen:
Die Unsicherheit der Antwort kann zunächst durch eine Analyse der Wahrscheinlichkeiten der generierten Token bewertet werden. Wie oben erwähnt, kann dies Informationen darüber liefern, ob eine andere Antwort ebenfalls sehr wahrscheinlich oder weniger wahrscheinlich wäre.
Andere Methoden zur Bewertung der Unsicherheit basieren auf Stichprobenverfahren, wie z. B. »Self-Consistency«. Dabei werden mehrere Antworten auf eine Abfrage erzeugt und analysiert, um zu beurteilen, ob das LLM immer ähnliche oder völlig unterschiedliche Antworten auf dieselbe Frage ausgegeben hätte.
Fakten prüfen:
Eine weitere Methode zum Erkennen von Halluzinationen ist die Faktenprüfung. Dazu werden die Ergebnisse des Sprachmodells mit einer Wissensdatenbank oder den Benutzereingaben verglichen werden. Dies kann helfen, falsche Informationen zu identifizieren und zu korrigieren. Auch hier sind verschiedene Strategien möglich. Grundsätzlich wird die Modellausgabe (z.B. Text bei LLM) mit vorhandenen Fakten (ebenfalls Text oder Wissensgraph) verglichen. Dies kann über klassische NLP-Vergleichsmetriken (z.B. BLEU, ROUGE, etc.), über semantische Ähnlichkeit oder über die Prüfung, ob bestimmte faktische Entitäten oder Entitätsbeziehungen (Ort, Datum, Organisationsname etc.) vorhanden sind, erfolgen. Andere Ansätze verwenden ein zweites (oder mehrere) LLM(s) als eine Art Prüfer, um Antworten und Fakten zu vergleichen.
Lösungsansätze zur Vermeidung von KI-Halluzinationen
Um das Problem von KI-Halluzinationen zu bewältigen, sind verschiedene Strategien erforderlich. Eine vielversprechende Maßnahme ist die sorgfältige Datenaufbereitung, die Deduplizierung und Debiasing umfasst. Darüber hinaus sollte das Training der KI-Modelle durch gezielte Architekturanpassungen verbessert werden. Solche Lösungen sind jedoch nur für Organisationen anwendbar, die generativen KI-Modell selbst trainieren.
Eine weitere Strategie besteht darin, den Ursprung der Halluzinationen in den Gewichten des Modells zu verstehen und das Modell zu »reparieren«. Diese Anpassung des trainierten Modells wird als »Knowledge Editing« oder »Representation Engineering« bezeichnet und ist derzeit ein Forschungsansatz, der noch keine breite Anwendung gefunden hat.
Ein praktischerer Ansatz ist die Verwendung von Prompting-Techniken wie »Chain of Thoughts« oder Architekturen wie »Retrieval Augmented Generation« (RAG), bei denen LLMs mit externen Wissensdatenbanken verbunden werden. Dies erhöht die Genauigkeit der generierten Informationen. In der RAG-Architektur werden die Stärken von LLMs für die Sprachverarbeitung genutzt, während das Sammeln von Fakten und das Ziehen von Schlussfolgerungen spezialisierten Werkzeugen überlassen wird.
Mehr zum Thema LLM und Gen AI
- Retrieval Augmented Generation (RAG): Chatten mit den eigenen Daten
- Prompt Engineering: Wie man mit großen Sprachmodellen kommuniziert
Insgesamt ist das Erforschen der Halluzinationen von LLMs von entscheidender Bedeutung, um die Zuverlässigkeit dieser Technologien zu verbessern. Da sich LLMs schnell weiterentwickeln, ändern sich auch die Methoden zum Erkennen und Vermeiden von Halluzinationen ständig. Unsere Expertinnen und Experten können Ihnen helfen, die besten Strategien für Ihre LLM-basierten Anwendungen zu entwickeln.
Referenzen
[1] Bolukbasi, Tolga, et al. „Man is to computer programmer as woman is to homemaker? debiasing word embeddings.“ Advances in neural information processing systems 29 (2016).
[2] Zhao, Yunpu, et al. „Towards Analyzing and Mitigating Sycophancy in Large Vision-Language Models.“ arXiv preprint arXiv:2408.11261 (2024).
[3] Ji, Ziwei, et al. „Survey of hallucination in natural language generation.“ ACM Computing Surveys 55.12 (2023): 1-38.
[4] Huang, Lei, et al. „A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.“ arXiv preprint arXiv:2311.05232 (2023).
[5] Ye, Hongbin, et al. „Cognitive mirage: A review of hallucinations in large language models.“ arXiv preprint arXiv:2309.06794 (2023).
[6] Rawte, Vipula, Amit Sheth, and Amitava Das. „A survey of hallucination in large foundation models.“ arXiv preprint arXiv:2309.05922 (2023).
[7] Zhang, Yue, et al. „Siren’s song in the AI ocean: a survey on hallucination in large language models.“ arXiv preprint arXiv:2309.01219 (2023).
[8] Tonmoy, S. M., et al. „A comprehensive survey of hallucination mitigation techniques in large language models.“ arXiv preprint arXiv:2401.01313 (2024).
[9] Liu, Hanchao, et al. „A survey on hallucination in large vision-language models.“ arXiv preprint arXiv:2402.00253 (2024).
[10] Bai, Zechen, et al. „Hallucination of multimodal large language models: A survey.“ arXiv preprint arXiv:2404.18930 (2024).