
Wie kann man KI-Systeme testen, und warum können schlechte Daten dabei helfen? In diesem Blogbeitrag erklärt unser KI-Experte Dr. Julien Siebert, wie man KI-Systeme durch Fehlerinjektion mit unserer Badgers-Bibliothek testen kann.
Auswirkungen mangelnder Datenqualität
Datenqualitätsprobleme sind bei der Entwicklung und Bereitstellung von KI- und ML-Anwendungen eine zentrale Herausforderung. Ungenaue, unvollständige oder inkonsistente Daten können zu falschen Ergebnissen führen. Daher ist es wichtig, dass Systeme in der Lage sind, mit solchen Unzulänglichkeiten umzugehen. Fehlerinjektion, d. h. die absichtliche Einführung von Fehlern in ein System, um dessen Robustheit zu bewerten, ist eine wichtige Methode, um zu beurteilen, wie KI-/ML-Anwendungen mit realen Datenproblemen umgehen.

Potenzial der Fehlerinjektion
Die Bedeutung der Fehlerinjektion liegt in ihrer Fähigkeit, potenzielle Schwachstellen in KI-/ML-Systemen aufzudecken, bevor diese in kritischen Umgebungen eingesetzt werden. Und nur ein methodischer Ansatz trägt dazu bei, die Zuverlässigkeit und Stabilität dieser Systeme unter ungünstigen Bedingungen zu gewährleisten. Die Erzeugung von Fehlern, die die Komplexität der realen Welt genau widerspiegeln, ist jedoch eine anspruchsvolle Aufgabe. Sie erfordert ein tiefes Verständnis der spezifischen Domäne und der Funktionalität des Systems, das die Daten erzeugt.
Ursache von Datenqualitätsproblemen
Probleme mit der Datenqualität können bei der Datenerhebung oder im System selbst auftreten. Messungen können ungenau sein, Daten können verloren gehen oder verändert werden, und Einschränkungen bei der Datenerhebung können zu unvollständigen Datensätzen führen. Das System selbst kann ausfallen, die Umgebung kann sich ändern, oder es treten Unterschiede in der Art und Weise auf, wie das System genutzt wird.

Datenqualitätsprobleme generieren
Fehler, die sich aus dem Prozess der Datenerhebung ergeben, sind relativ einfach zu erzeugen, da sie weitgehend unabhängig von der Funktionsweise des Systems sind. Im Prinzip können solche Fehler den vorhandenen Daten hinzugefügt werden. So kann z. B. weißes Rauschen hinzugefügt werden, oder Werte können zufällig gelöscht werden.
Fehler, die aus einer Änderung des Systems selbst resultieren, sind schwieriger zu erzeugen, da sie ein Verständnis der Systemfunktion und der Datengenerierung erfordern. Dieses Verständnis des zugrundeliegenden Systems kann entweder von Domänenexperten oder aus der Theorie (d. h. der Physik des Systems) stammen. Das Problem ist, dass ML-/KI-basierte Softwarekomponenten genau dann eingesetzt werden, wenn dieses tiefe Verständnis fehlt. Das heißt, wenn nur Daten vorhanden sind, aber keine/wenig Theorie darüber, wie die Daten generiert wurden (siehe auch unseren Blogbeitrag zu diesem Thema: Datenqualität und Kausalität).
BADGERS: Bad Data Generators
Unsere Open-Source Badgers-Bibliothek (Code: https://github.com/Fraunhofer-IESE/badgers, Dokumentation: https://fraunhofer-iese.github.io/badgers/) hat zwei Hauptziele:
- Den Stand der Technik bei der Generierung von Datenqualitätsdefiziten sammeln und über eine einfache API zugänglich machen.
- Eine einfache Möglichkeit bieten, systematische Robustheitstests von ML-basierten Komponenten durchzuführen.
Das Grundprinzip der Badgers-Bibliothek besteht darin, vorhandene Daten zu transformieren, indem Datenqualitätsmängel wie Ausreißer, Rauschen, fehlende Werte, Drift usw. eingefügt werden.
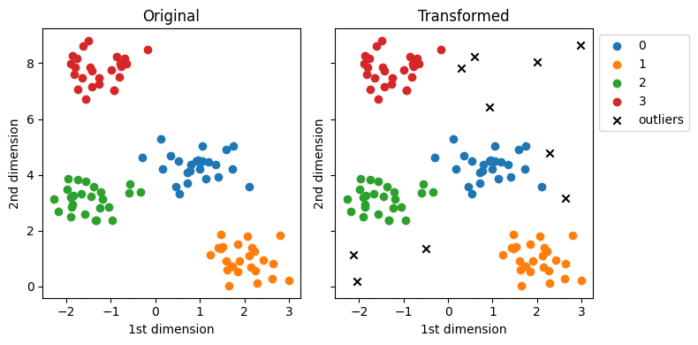
Das Herzstück der Badgers-Bibliothek sind die so genannten Generatoren-Objekte. Sie sind nach Art der Daten (Modalität) und nach Art des Datenqualitätsproblems organisiert. Jeder Generator implementiert eine Generierungsfunktion generate(X,y), die die Features X und die Labels (oder Ziele) y als Eingabe nimmt und die modifizierten Daten X_transformed und Labels y_transformed zurückgibt.
Der folgende Code zeigt zum Beispiel, wie man aus Tabellendaten Ausreißer erzeugen kann:
trf = LowDensitySamplingGenerator(n_outliers=10, threshold_low_density=0.25)
outliers, _ = trf.generate(X.copy(), y, max_samples=100)
Die Bibliothek ist derzeit in Entwicklung. Einfache, aber effektive Rezepte zur Erzeugung von Qualitätsproblemen in verschiedenen Modalitäten (tabellarische Daten, Zeitreihen, Text, Diagramme) sind bereits implementiert. Mehrere Tutorials sind hier verfügbar: https://fraunhofer-iese.github.io/badgers/
Mehr zum Thema Kausalität und Datenqualität:
- Causal inference:
An introduction on how to separate causal effects from spurious correlations in data - Datenqualität und Kausalität
bei auf Machine Learning basierender Software
Referenzen
Siebert, Julien, et al. „Badgers: generating data quality deficits with Python.“ arXiv preprint arXiv:2307.04468 (2023).
Siebert, Julien, et al. „Construction of a quality model for machine learning systems.“ Software Quality Journal 30.2 (2022): 307-335.
Siebert, Julien, et al. „Towards guidelines for assessing qualities of machine learning systems.“ Quality of Information and Communications Technology: 13th International Conference, QUATIC 2020, Faro, Portugal, September 9–11, 2020, Proceedings 13. Springer International Publishing, 2020.