
Current industrial production scheduling approaches assume that process planning is performed before scheduling and that process plans are fully or at least partially available before scheduling starts. However, this is not the case in service-based production [5]. Service-based production provides a production environment where production processes are frequently adapted because new product types are introduced or machines are newly installed. In such cases, not only do the current schedules have to be adapted, but the process plans must also be re-orchestrated. Hence, process planning and scheduling must be considered in an integrated way.
In this Fraunhofer IESE blog post, we show an approach using a Reinforcement Learning (RL) algorithm to perform integrated process planning and scheduling for service-based production. We use n-step Deep Q Learning (DQN) [3] to train an agent that can synthesize process plans and derive near-optimal schedules. In this article, we define the target problem for integrated process planning and scheduling and present the first RL design for individualized production in detail. You can find the original work with more detail here.
Problem definition
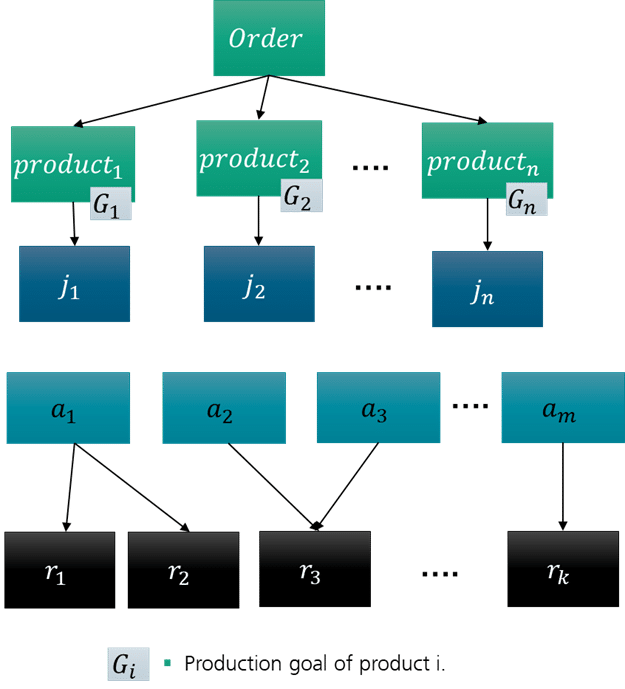
Figure 1 specifies the IPPS problem. It defines all necessary input data for the modeling of the data necessary for our approach. There is an incoming order, which includes a set of customized products. Each product is individual; its requirements are formulated as a production goal. Using the production goal, our approach synthesizes the process plans for this individual product from scratch. The production goal consists of a set of goal attributes. A goal attribute is a data element that describes the value, type, and further information of a data element. The set of goal attributes specifies the expectation of the final product.
In the scheduling, the production of a product instance is considered a job. For n ordered product instances, there are a total of n jobs. Each job has a property list that represents the current status of the job. The content of the property list corresponds to the goal attributes of its production goal.
Meanwhile, available services are represented as a set. Each service has one or multiple service providers, which are resources. A resource can be a device, a machine, a workstation, or a human worker. Available resources can be defined as a set .
Deep Reinforcement Learning essentials
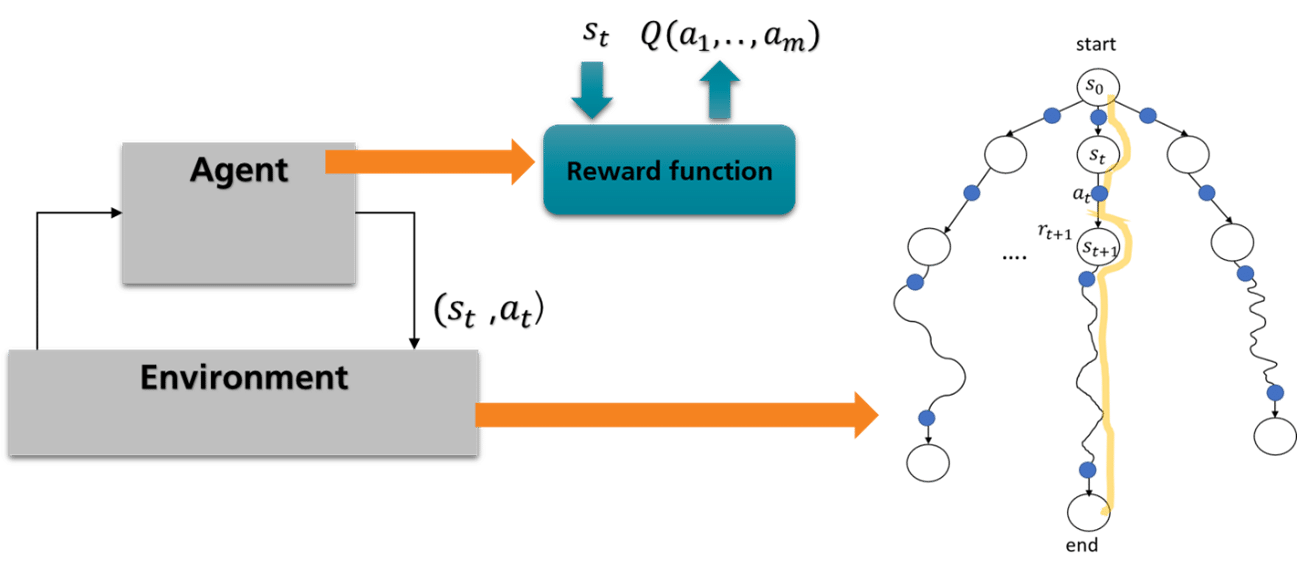
Before we dive into the details of the RL designs, we want to give a brief overview of the essentials of DQN theory. In an RL framework, there is an agent that learns a policy by interacting with an environment in repeated time steps. The RL environment models the behavior of the real production system as a Markov Decision Process consisting of a set of states, state transitions, and rewards.
At each time step, the agent selects an action from the action space and involves it in the environment. The execution of the action triggers a state transition and generates a reward. The reward and the new state are returned to the agent. The above process generates an experience sample, where s_t denotes the current state, a_t represents the selected action, R_{t+1} denotes the reward, and s_{t+1} is the new state after the state transition. The agent gathers a lot of experience samples by repeating a dozen of the time steps. It uses the samples to approximate a function that evaluates the quality of the actions for the current state. The input of the function is the current state, and the output of the function are the assessments for each action. The assessments represent how good it is to execute an action in the current state. The search path from the start state to the end state is an episode. The agent must repeat many episodes to learn an optimized policy.
Hence, for each Deep Reinforcement Learning-design, we need to consider the following three questions:
1. What does the action space look like?
2. What information should be included in a state?
3. How to model the rewarding system? These three questions are answered in the following sections.
Holistic process planning and scheduling with Reinforcement Learning
The first Reinforcement Learning design is called holistic process planning and scheduling. It performs process planning and scheduling at the same time. This means that, before the agent finds a completed process plan, it has already begun the scheduling of multiple jobs. This design is aimed at individualized production with small lot sizes.
What does the action space look like? What information should be included in a state?
The action space is composed of all available services and an idle service. The idle service means that no action is taken at the current time step. A state contains information on all job states and resource states. A job state reflects the current job status, and a resource state the current resource status.
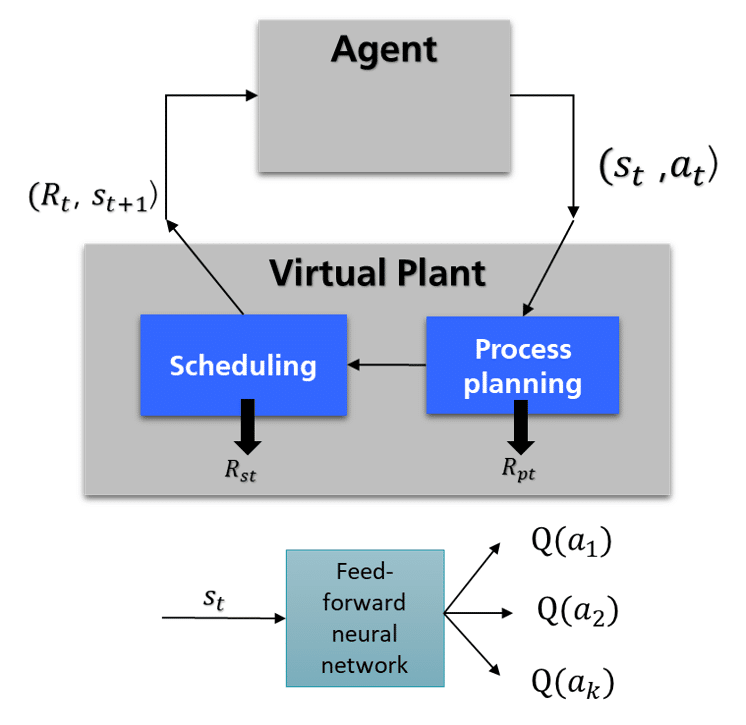
Figure 3 shows the details of the first RL design. This design contains an agent and a virtual plant that serves as the RL environment. The virtual plant has a planning module and a scheduling module. At each time step, the process planning module is started first and the scheduling module is started afterwards. The action space of this design can be formulated as A={a_1, a_2, …,a_k} U a_{idle}, where a_{idle} means no action is taken at the current time step. The {a_1, a_2, …,a_k} is the set including all available services defined in Figure 1.
The state space can be formulated as S=S_{jobs} x S_{resources}. It is a Cartesian product of the job space and the resource space. The job states can be formulated as s_{jt}={s_j1, s_j2,…,s_jn}, and the resource states as s_{rt} ={s_r1, s_r2,…,s_rn}. A job state is the sum of the values of the job properties. A resource state is the sum of the values of the resource properties. This design uses a feed forward neural network to approximate the reward function.
How to model the rewarding system?
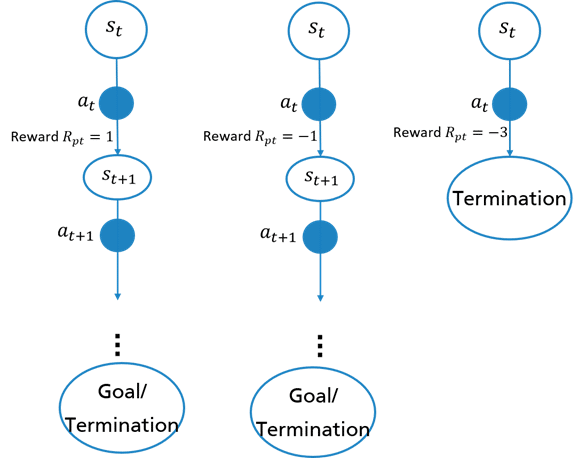
The process planning module and the scheduling module are responsible for generating dense rewards at each time step. The process planning module examines whether the selected service is executable in the current state and generates a reward based on service executability. Figure 4 shows how rewards are generated based on service execution. The first path shows that the service is executable in the current state and a positive reward is generated. In this case, the agent can continue with the service until it reaches an end state. The second path shows that the selected service has no influence on the current state. In this case, a lower reward is returned and the agent can also continue with the search until it reaches an end state. The third path shows that the selected service results in damage of the current state. In this case, a negative reward is returned and the current episode is terminated.
If the selected service is executable, the scheduling module is started after the process planning module. The scheduling module is responsible for managing the running services. It keeps an internal list of running tasks because the duration of a service crosses multiple time steps. At each time step, it loops through each task in the list and checks whether the service ends at the current time step. If this is the case, it marks the service as completed and puts it in another list. This module generates a dense reward based on mean machine utilization. The final reward is the weighted summation of both rewards.
Conclusion
In this blog, we have presented the data models used by our scheduling approach and the first Deep Reinforcement Learning design for individualized production with small lot sizes. This design is adequate for cases where process plans must be re-synthesized frequently due to individualized product requirements.
Are you looking for more information on the topic of Deep Reinforcement Learning?
In our next blog article in this series, we will present the second RL design, which can schedule continuously incoming jobs with large job quantities.
Also, don’t hesitate to contact our experts!