
The verification and validation of software components are based on extensive testing. The required test cases to enable testing are derived from the specified requirements, which are then executed, and the results are compared with the acceptance criteria of the test cases. Even for relatively small systems, the derivation of test cases is a resource-intensive and therefore expensive endeavor. Assuming a conservative estimate of 5–10 minutes per test case, it may take more than twenty person-days of effort to write test cases for a system with around 500 requirements. By leveraging Large Language Models, (LLMs), we can increase the efficiency of test case generation.
The development of complex systems starts with their requirement specifications. For dependable and safety-critical systems, this also includes safety requirements based on the safety analysis of the system. Deriving the test cases manually for these requirements is a time-consuming process. However, by leveraging LLMs, we can improve this process. As input for the LLM, a textual representation of the requirements is used, which is then autonomously transformed into test cases and scenarios in either plain-text format or any formal specification, such as ASAM Open Test Specification. The current best practice of test case reviews by test engineers can ensure the integrity and correctness of these test cases. By using LLMs, the work of the test engineer can be reduced by focusing on formulating test cases for edge cases and reviewing and refining the automatically derived test cases and scenarios.
Using Large Language Models can significantly reduce the time and costs needed to generate test cases.
LLM-based test case generator
| Requirement ID | Requirement ID Reqif | Category | Requirement Description |
|---|---|---|---|
| 1.1 | R001 | Lane Detection | The system shall detect lane markings on the road using cameras and/or sensors. |
| 1.2 | R002 | Lane Detection | The system shall identify lane boundaries under various lighting and weather conditions. |
| 2.1 | R003 | Lane Departure Warning | The system shall provide a warning to the driver if the vehicle is unintentionally drifting out of the lane. |
| 2.2 | R004 | Lane Departure Warning | The warning shall be provided through visual, auditory, and/or haptic feedback. |
| 3.1 | R005 | Steering Assistance | The system shall gently steer the vehicle back into the lane if it detects an unintentional departure. |
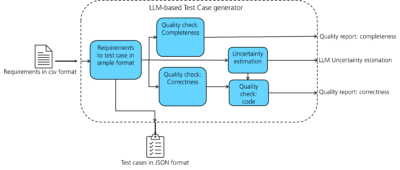
To maintain confidentiality of the requirements and the generated test cases, internally deployed LLM models are used.
Automated test case generation
Large language models generate their output based on prompts. For generating the test cases, one can start with a simple prompt, such as “Generate the test case for the following requirement.” However, this may not yield the desired result. Studies have shown that LLMs are easier to work with when provided with prompts that are as concise as possible. Using the guidelines of the standards ISO 26262, we settled on a prompt that specifies in detail the expected output characteristics and attributes of a test case specification.
Quality evaluation
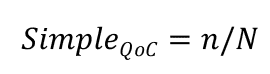
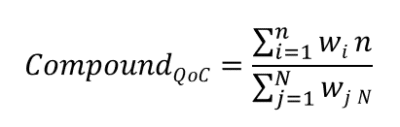
| Sl No | Criteria | Satisfied Yes/No | Comment |
|---|---|---|---|
| 1 | Language is simple and straightforward | ||
| 2 | Steps are specific and detailed | ||
| 3 | Steps are clear and unambiguous | ||
| 4 | Consistent terminology and format used | ||
| 5 | Inputs are clearly defined |
Uncertainty evaluation
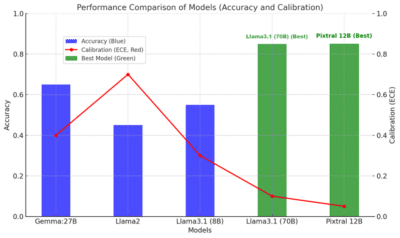
Out of all the evaluated models, LLaMA3.1 (70B) and Pixtral were found to be best performant.
Conclusion for software testing
References
- ISO 26262 Road vehicles – Functional safety
- ISO 29119 Software and systems engineering — Software testing
-
Agrawal, Pravesh, et al. „Pixtral 12B.“ arXiv preprint arXiv:2410.07073 (2024).
-
Touvron, Hugo, et al. „Llama 2: Open foundation and fine-tuned chat models.“ arXiv preprint arXiv:2307.09288 (2023).
-
Dubey, Abhimanyu, et al. „The llama 3 herd of models.“ arXiv preprint arXiv:2407.21783 (2024).
-
Team, Gemma, et al. „Gemma 2: Improving open language models at a practical size.“ arXiv preprint arXiv:2408.00118 (2024).
-
Cobbe, Karl, et al. „Training verifiers to solve math word problems.“ arXiv preprint arXiv:2110.14168 (2021).
-
Hendrycks, Dan, et al. „Measuring massive multitask language understanding. (MMLU)“ arXiv preprint arXiv:2009.03300 (2020).