
A core technology in realizing Industry 4.0 is the Asset Administration Shell (AAS) as an implementation of the Digital Twin. The AAS enables interoperable data-sharing in a company as well as within a network of companies, creating an AAS dataspace. To create this AAS dataspace, however, data in Systems of Record (SOR) such as ERP, PLM, and quality databases must be available as AASs. SORs typically form data silos that lack interoperability due to custom data models and interfaces that are typically incompatible with the native Industry 4.0 communication. Very little guidance or even tooling is available on integrating SORs into the AAS dataspace in a reusable and scalable way. This blog post shows architectural solutions and concepts to narrow this gap, thus enabling quick integration of existing SOR with the AAS dataspace. Additionally, it provides an open-source implementation bridging this gap. The configurations of the proposed solution and how it works will be discussed using a real-world example in Part 2 of this blog post.
An AAS is a virtual representation of assets that connects physical assets with the digital world. It contains multiple submodels that describe an asset’s information and functions, such as its features, properties, parameters, and measurement data. It enables various communication channels and applications and bridges objects and the digital world [1]. As of today, a lot of data exists in Systems of Record (SOR) [2], such as ERP, PLM, and quality databases. These SORs provide a multitude of interfaces, data structures, and interaction patterns. Thus, the integration of Industry 4.0 users with an existing SOR landscape may involve costly tailoring if not tackled in a smart way. A common platform can create interoperability and thus drastically reduce integration effort.
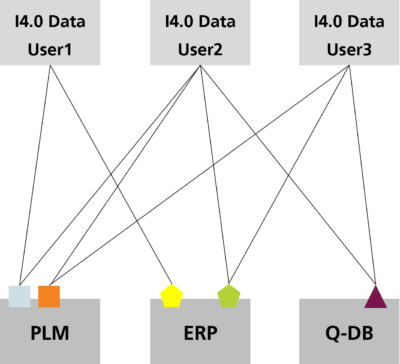
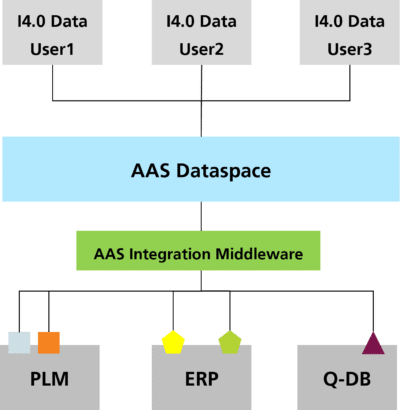
The data contained in an SOR needs to be available as a AAS for further processing and aggregation as well as provision in the AAS dataspace. However, due to a lack of interoperability, this data is not accessible directly. Complete migration or a Big Bang transition from SOR to AAS is not a good approach due to the cascading effect [3]. In consequence, integration of data from SOR into AAS is needed that avoids Big Bang transitions while still ensuring that the data can be made available in the AAS dataspace. However, this raises the following two significant issues:
- How to enable automated SOR integration?
- How to efficiently integrate SOR for different scenarios?
The first challenge is already solved by highly customized applications such as BaSysPLM [4] and BaSys4SupplyQ [5]. However, these are optimized for specific use cases and thus are not applicable for generic integration. There is a need for a solution that generalizes for use cases and provides efficient integration patterns. This challenge is depicted in Figure 3.
Challenges of integrating SORs
Integrating data from various SORs (PLM, ERP, quality databases) into the AAS dataspace takes considerable work as these SORs are not designed to work with AASs directly, meaning compatibility problems can arise, as depicted in Figure 1.
Below are some of the challenges associated with integration:
Big Bang transition
For data integration into the AAS dataspace, one approach could be to transform or map all the data in the SOR as AASs and store it in a repository. Then that repository could be used whenever there is a request for an AAS. Once all the data has been integrated, it can be safely deleted from the SORs. Integrating all the data at once from SORs is known as the Big Bang transition or Big Bang adoption [6].
However, there are some challenges or limitations in doing this. There might be a need for the data present in SORs due to other pre-existing systems depending on the specific data models and interfaces of the SOR. So, removing all the data from SORs is not feasible most of the time. However, keeping the data in SORs as well as in AASs is not a good approach either, since it is a direct violation of the data deduplication principle [7].
Common interface for SORs
Some SORs have an HTTP/REST-based interface to access the appropriate data. In contrast, others provide direct access to the database, such as SQL, No SQL, or any other storage base. So, the communication interface varies depending on the type of SOR. Accessing the data from HTTP-based SORs requires certain properties for establishing connection, while SQL-based SORs have completely different requirements. The communication interface varies even between similar kinds of SORs. For example, the Structured Query Language (SQL) is used in all relational databases. However, the connection properties may vary depending on the database management system. This variation is also present in non-relational databases [8].
Reading data from multiple SORs
The data could be scattered among many SORs. In other words, the AASs may require data from not only one SOR but from any number. For example, if there is a need to integrate address data into an AAS for a Digital Nameplate, and the cities are stored in one SOR, e.g., an SQL-based database, and the postal codes come from HTTP/REST-based SORs, then aggregating data from these two unrelated systems is challenging as the data format varies. It is common for some SORs to employ different standards, protocols, and data formats to store and transfer data. The differences in these variations can pose a challenge in creating a uniform data model for aggregation.
Looking for possible AASs inside an SOR
The AAS Registry server is used to retrieve the descriptors of all the registered AASs, i.e., to learn about which AASs exist and where to find them. SORs can possibly contain the data relevant to millions of AASs. Knowing about a certain AAS presence within an SOR is quite challenging. There may be a need to do some complex operations to find a possible AAS because it might not be identified directly.
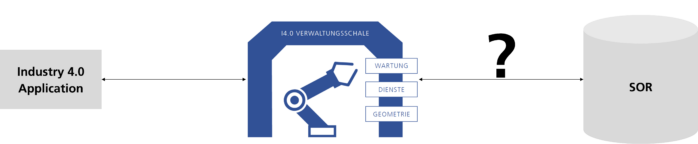
Solution architecture of SOR integration with the AAS dataspace
The proposed solution architecture overcomes the challenges defined in the previous section and provides a middleware that can integrate the data from various kinds of SORs into the AAS dataspace, as depicted in Figure 4. The proposed solution addresses the two questions raised in the problem description.
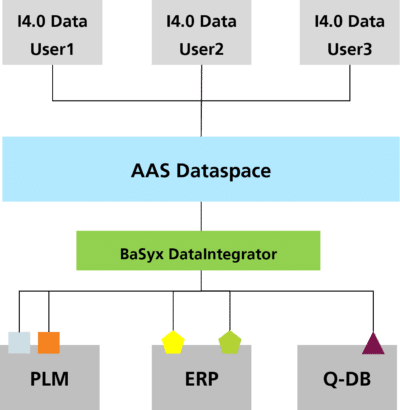
The proposed solution architecture takes configurations and SOR data sources as inputs and provides the resultant integrated AAS or AAS descriptors as output, as shown in Figure 5. By providing AASs on-the-fly based on the data of the SOR, data deduplication principles are followed.

The DataIntegrator component is the main component that creates the AAS or AAS Descriptor from the data within the SOR. The architecture is designed in a pipeline pattern consisting of reading, processing, and writing/integrating the data. However, such a system requires configuration effort. While this configuration can be done in any way, it would be ironic if a solution to this challenge were to lead to another data silo. In consequence, a submodel-based configuration promises to create interoperability not only on the layer of the data itself but also on the layer of the integration configuration. For asset integration, for example, the Asset Interface Description Submodel follows a similar approach.
In consequence, the BaSyx DataIntegrator supports a submodel-based configuration, i.e., both the configuration and the SORs connection information are provided as a submodel.
BaSyx DataIntegrator Pipeline
The previous section discussed that the proposed solution architecture is designed in a pipeline pattern. In consequence, the internal structure of the BaSyx DataIntegrator is divided into Integrator units. These units are isolated from each other and have a strict separation of tasks to be performed in a sequential manner. For the BaSyx DataIntegrator, three units are specified: reader, processor, and writer. The flow from the reader to the writer makes a DataIntegrator pipeline, as shown in Figures 6 and 7. The readers read data from the SOR, pass the data onto the processors for transformation, and then the processed data is passed to the writers for creating AAS or AAS Descriptors based on the use cases.
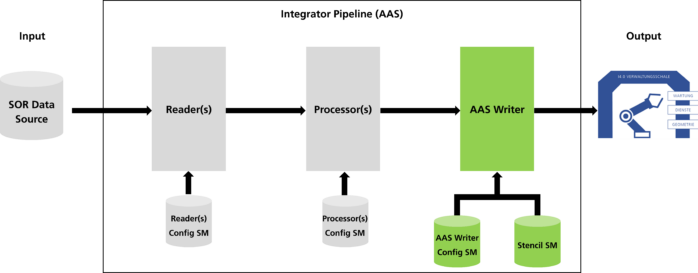
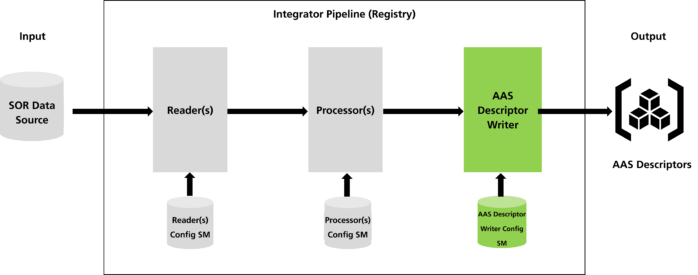
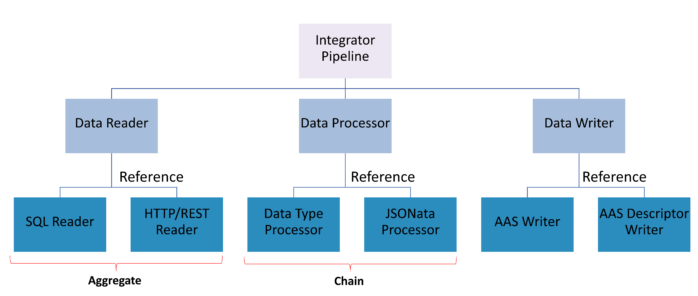
Figure 8 shows the hierarchical view of the BaSyx DataIntegrator pipeline. The intermediate units are the generic units for the reader, processor, and writer. The units at the bottom of the hierarchy are the concretely supported types. There is a possibility to use multiple readers and multiple processors in a pipeline. The data from multiple readers is aggregated while the processing happens through a series of processors in a chained fashion. All these Integrator units and the Integrator pipeline are configured very easily using the submodel.
Below is a detailed explanation of each Integrator unit:
Data Reader
The data reader acts as a connector between the data sources (SORs) and the other Integrator units. The primary purpose of the data reader is to read the data from outside sources like databases, files, or APIs and map it into a format appropriate for additional processing.
SQL- and HTTP/REST-based data readers are currently supported. While the two readers are of entirely different types, they are integrated into a consistent architecture that enables quick implementation of additional readers.
Data Processor
The data processor is used to transform the read data into the format desired by the target, which is an AAS. The proposed data integration system currently supports two types of data processors, the data type processor used for type conversions and the JSONata [9]-based processor, which can be leveraged for more complex transformations.
Data Writer
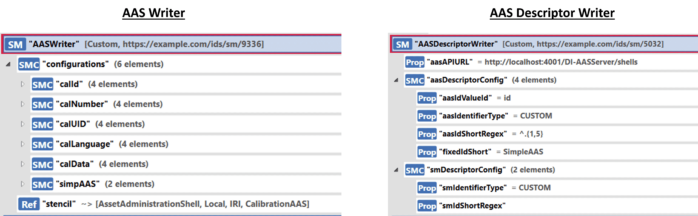
The data writer is an essential part of the BaSyx DataIntegrator system as it manages the final stages of the data integration procedure. After reading and processing the data, the data writer generates the AAS or the AAS Descriptors. Currently, two kinds of data writers are supported: the AAS Writer and the AAS Descriptor Writer.
Apart from the submodel-based configurations, the AAS Writer also takes an AAS stencil as input. An AAS stencil is the predefined structure that specifies the skeleton of the resultant AAS from the BaSyx DataIntegrator system. The AAS stencil is a standard Type 2 AAS [10]. No stencil is required for the AAS Descriptor Writer.
Submodel-based configuration
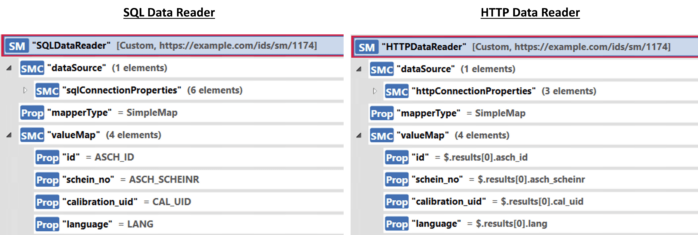
As explained in the previous sections, each of the Integrator units is fully configurable using submodel-based configurations like the proposed integration of devices via the Asset Interface Description Submodel [14]. In consequence, the whole Integrator pipeline comprised of Integrator units is configurable using a submodel. The submodel-based configurations for data readers, processors, and writers are shown in Figures 9, 10, and 11, respectively. For more details, see [11].

Configuration at runtime
The proposed BaSyx DataIntegrator system supports modifications in configurations at runtime without restarting the system. The modifications include adding new configurations, updating existing configurations, and removing configurations. Figure 12 shows the overall configuration architecture involving the Configuration Change Listener as a part of the proposed system, leveraging the features of Eclipse BaSyx for easier integration.
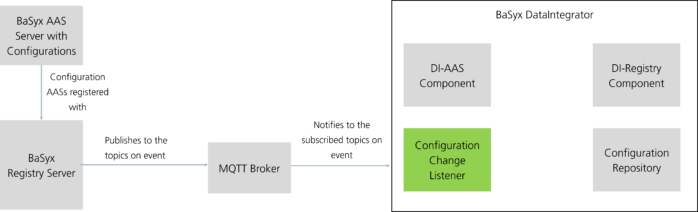
The BaSyx AAS configuration server acts as a central repository for storing submodel-based configurations. The Configuration Change Listener is connected to the MQTT broker to listen to changes in the submodel-based configurations registered with the BaSyx Registry Server. Whenever a new submodel-based configuration is added to the BaSyx AAS Server, the configuration is automatically applied to the system using the Configuration Change Listener. This enables plug’n’playability support to the system, which, in consequence, can be leveraged by users for a seamless (re-)configuration of the integration system.
Benefits and future of the BaSyx DataIntegrator
The proposed BaSyx DataIntegrator system addresses the challenges of integrating SORs with AASs in order to make these available in the AAS dataspace while avoiding the drawbacks of a Big Bang transition. It provides an efficient, scalable, and maintainable architecture and as well as an implementation for integrating data from various SORs into the AAS dataspace. The whole system is very easy to configure using the submodels only; hence, no programming knowledge is required. It also provides functionality to peek into the SORs and retrieve the descriptors of all the AAS candidates present. This helps to know the exact AASs required instead of requesting all the AASs from an SOR and filtering them out. The system can adapt to changes in configurations during runtime, so no downtime is required. It is very easy to add any new SORs to the system in the form of plug-and-play. The interfaces of both the DI-AAS component and the DI-Registry components are the same as for the BaSyx AAS Server and the BaSyx Registry Server, respectively. It is implemented and provided as an open-source off-the-shelf component [11].
Support for additional SORs such as MongoDB will be provided in future updates. The focus will also be on supporting more complex transformations using some complex data processors. Future work will include support for version 3 conformance of the specification of the AAS. The configuration and a real-world integration example will be discussed in the second part of this blog series.
References:
[1] Platform Industry 4.0. Asset Administration Shell Reading Guide. https://www.plattform- i40.de/IP/Redaktion/DE/Downloads/Publikation/AAS-ReadingGuide_202201.pdf?__blob=publicationFile&v=1
[2] System of record. (2023, September 27). In Wikipedia. https://en.wikipedia.org/wiki/System_of_record
[3] Bundesministerium für bildung und forschung. “BaSysPLM – BaSys 4.0-integriertes Product Lifecycle Management”. In: (2019).
[4] Bundesministerium für bildung und forschung. “BaSys4SupplyQ – BaSys 4.0 Vernetzung der Supply Chain am Beispiel von Qualitätsdaten”. In: (2019).
[5] “Big bang adoption”. In: Wikipedia (2022). url: https://en.wikipedia.org/wiki/Big_bang_adoption.
[6] Simanta Shekhar Sarmah. “Data migration”. In: Science and Technology 8.1 (2018), pp. 1–10.
[7] “Non-Relational Databases”. In: Amazon AWS (2018). https://aws.amazon.com/nosql/.
[8] JSONata Documentation. url: http://docs.jsonata.org/overview.html.
[9] Type 2 AAS. https://wiki.eclipse.org/BaSyx_/_Documentation_/_AssetAdministrationShell
[10] Asset Interface Description Submodel https://github.com/admin-shell-io/submodel-templates/tree/main/development/Asset%20Interface%20Description/1/0
[11] BaSyx DataIntegrator https://github.com/eclipse-basyx/basyx-applications/tree/main/dataintegrator